Partitioned Clustered Columnstores - Mind your deltastores!
We use an hourly partitioning scheme coupled with a clustered columnstore to support ingestion and short-term retention of various telemetry data. A fairly common pattern is for us to deploy an hourly partition schema based on the InsertDate of data (a column with a default of getutcdate()).
One thing we've had to keep an eye on when using this kind of pattern is the number of open deltastores that can get left behind as inserts 'move on' to a new partition.
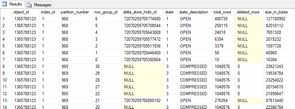
Hourly partitions are used as they are also the unit of truncation as data ages out in our environment. Due to the pain of the 'dangling deltastores' (as well as high partition counts impacting DMV usage) we're looking at making daily the smallest partition size we support.
When partitioning a clustered columnstore table you will have one or more deltastores per partition. The largest I've seen so far is 20 open in a single rowgroup (with row counts ranging from 1M to 10k), though 4 is about average for this particular environment.
These open deltastores have a number of drawbacks:
- Increased size on disk for uncompressed rows
- Lack of rowgroup elimination for the rows in the deltastores
- Reduced query performance on queries which work in the rowstores
The rest of this post will cover these in a bit more detail, as well as how to see if you're impacted and what to do about.
Increased size on disk
The first example is best shown by a table which had escaped any kind of index maintenance:

The deltastores might be less than 20% of the rows, but they're more than 80% of the space used for the table! In the example above compressing the open rowgroups reduced the table from 500GB to 150GB.
Lack of rowgroup elimination
Rowgroup elimination is the ability of a query against the columnstore to skip entire rowgroups based on the metadata about min/max values stored for each column segment in the rowgroup (see sys.column_store_segments). When querying our telemetry table for a single record in the last day (already leveraging partition elimination to limit our query), we'll also supply a predicate for a ServerId we know doesn't exist. This is beyond the max value that should exist in any rowgroup.
select top 1 *
from dbo.Telemetry as t
where t.ServerId = 99999999
and t.InsertDateTime>= cast(getutcdate() - 1 as datetime2(3));Partition elimination won't work if your data types are more precise than the column you're partitioning on. In our case using
getutcdate()would have been converted to datetime2(7), more precise than ourInsertDateTimecolumn which isdatetime2(3), resulting in a full table scan [ouch]. Segment elimination has no such qualms about data type precision!
Table 'Telemetry'. Scan count 101, logical reads 1548578, physical reads 0, read-ahead reads 1363208, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Telemetry'. Segment reads 0, segment skipped 107.
SQL Server Execution Times:
CPU time = 7672 ms, elapsed time = 9444 ms.
The statistics of this query show that every segment was skipped (they were successfully eliminated), yet we spent 10 seconds doing an awful lot of reads. These reads were against the deltastores, as SQL Server had to check every single row to ensure none of them were for ServerId 99999999.
Reduced query performance
In addition to a lack of rowgroup elimination, there are additional performance issues when operating against deltastores. Although deltastore scans do seem to benefit from batch mode, they don't benefit from aggregate pushdown.
Take the following query:
declare @cutoff1 datetime2(3) = '20180309';
declare @cutoff2 datetime2(3) = '20180310';
select count(*)
from dbo.Telemetry as t
where t.InsertDateTime >= @cutoff1
and t.InsertDateTime < @cutoff2;The results when executed against our table with many open deltastores:
Table 'Telemetry'. Scan count 114, logical reads 1589897, physical reads 235, read-ahead reads 1588889, lob logical reads 79781, lob physical reads 24, lob read-ahead reads 246172.
Table 'Telemetry'. Segment reads 150, segment skipped 3.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 18062 ms, elapsed time = 12791 ms.
And the results when executing against the same table where all deltastores have been compressed:
Table 'Telemetry'. Scan count 2, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 97544, lob physical reads 61, lob read-ahead reads 292647.
Table 'Telemetry'. Segment reads 259, segment skipped 6.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 641 ms, elapsed time = 435 ms.
A tidy 30x reduction in CPU.
How to check if you're impacted
The dmv sys.column_store_row_groups tells you the status of each of your row groups - you're looking for any open row groups that are no longer being inserted into, which is extremely common if you partition by an ever-increasing datetime value, more so as you have smaller partitions.
select object_name(rg.object_id) as TableName
,rg.*
from sys.column_store_row_groups as rg
where rg.state_desc = 'OPEN'You can also use Niko's Columnstore Indexes Script Library (CISL) to get a wealth of information about your columnstore indexes.
If you have a lot of partitions some of these DMVs can be very slow - I'd suggest dumping them into a #temp table for querying/analysis.
Fixing the problem
The good news is fixing this is easy:
alter index CCS_Telemetry on dbo.Telemetry reorganize
with (compress_all_row_groups = on);Although the command is easy, the impact to your system if you have a lot of open rowgroups might not be! You might instead opt to only compress a subset of partitions (much more typical if you have active partitions accepting inserts):
alter index CCS_Telemetry on dbo.Telemetry reorganize
partition = (1,2,3)
with (compress_all_row_groups = on);The final clause (compress_all_row_groups) refers to the row groups in the partitions, not all row groups in the table.
More information about index maintenance is available in the MSDN article Columnstore indexes - defragmentation.