Pattern - SQL Server as a shared cache for expensive stored procedures
The following scaling rules will take you a long way if you are supporting an environment with a SQL Server datastore:
- Cache as much as you can in the application tier
- Offload as much computation into the application as possible
- Minimise the work high-volume queries have to do
- Limit the number of transactions you do, and the work each transaction does
Knowing when to ignore (or even break) these rules is what keeps the job interesting.
The rest of the post will walk through a generic pattern to cache stored procedure results that vary by parameter, including the logic needed to expire, clean up, and evaluate the cache. This solution has been battle tested in production with a fairly expensive procedure called concurrently from multiple application nodes (for dozens of different parameter combinations).
The environment that motivated this work already aggressively caches results in the application tier - the specific motivation to cache the results in SQL came from the number of application nodes increasing. Building a shared cache service [or introducing something like Redis/Memcached] is a non-trivial engineering project, and the SQL CPU pressure this proc caused was significant. Other options (e.g. incremental cache updates/aggregation in the application tier) were also judged to be significant projects (or at least, more significant than caching it in the database!).
If you want to see the full example, you can check the complete source on GitHub. Before deploying into production I strongly suggest reading through the entire post for caveats and trade-offs.
The problem
For this worked example we're going to use a procedure that gets the top selling products for a given category - something like Amazon's category page which shows the top sellers.
create procedure dbo.GetTopSellingProducts
@categoryId int
as
begin
select top(20)
p.ProductId
,sum(s.TotalSalePrice) as TotalSalePrice
from dbo.Sales as s
join dbo.Product as p
on p.ProductId = s.ProductId
where p.CategoryId = @categoryId
and s.SaleDateTime > getutcdate() - 1
and p.AvailableStock > 0
group by p.ProductId
order by sum(s.TotalSalePrice) desc;
endWhile this procedure might only take 2 seconds to run (and be subsequently cached for a few minutes), we're potentially calling it _categories _ nodes* times per cache duration. If we assume our cache duration is 5 minutes, and we have 100 categories and 10 nodes, that comes to 400 CPU-seconds per-minute, 10x what it could be.
In a perfect world deploying this solution would always reduce the time spent by a factor of
number of nodes. The time spent on managing the cache is negligible, and the places where you lose perfect scaling tend to come from concurrent calls - this was an explicit design decision where preferring the proc to execute and cache multiple copies of the result set was preferable to a solution that uses locking to ensure only one session could update the cache at a time.
Cache solution
The solution comprises of a few different pieces:
- A master control table to toggle caching on/off
- A control table per-proc to keep track of what is available in the cache
- A results table per-proc which acts as the cache
- A clean-up procedure, which can be used to periodically clean the results
- The stored procedure itself, which is augmented with caching logic
The reasons why there exist control tables as well as results tables are discussed in more depth in the Tradeoffs and design decisions section below.
Tables
create schema DBCache authorization dbo;
go
create table DBCache.MasterControl
(
CachedEntity varchar(255) not null
,IsEnabled bit not null
,constraint PK_MasterControl
primary key clustered (CachedEntity)
);
go
create sequence DBCache.SEQ_Control as int
start with 1
increment by 1
cycle;
go
create table DBCache.dbo_GetTopSellingProducts_Control
(
CacheDateTime datetime2(3) not null
,ExpiryDateTime datetime2(3) not null
,Param_CategoryId int not null
,UseCount int null
,Id int not null
,constraint PK_dbo_GetTopSellingProducts_Control
primary key clustered (Id)
,index IX_dbo_GetTopSellingProducts_Control_ExpiryParams
nonclustered (Param_CategoryId, ExpiryDateTime)
);
go
create table DBCache.dbo_GetTopSellingProducts_Results
(
ControlId int not null
,ProductId int not null
,TotalSalePrice money not null
,index CIX_dbo_GetTopSellingProducts_Results
clustered (ControlId)
);
goEach stored procedure that needs to be cached has a control/result table that are unique to that stored procedure. Specifically, we capture all parameters in the control table, and all output columns in the results table. The control table must be indexed based on both the parameters of the procedure and the expiry date to support efficient lookups (answering the question 'is there a valid cached result for my parameter set?').
Ensure the types and nullability of these columns match what the stored procedure already uses/produces. A great way to get the type information of the result set is to use sp_describe_first_result_set
Stored Procedure
The stored procedure shown above changes drastically when we add caching. The complexity tradeoffs are discussed in more detail in the sections below.
The generalised stored procedure flow for a procedure that has caching looks something like this:
- Lookup the caching status from the master control table (on/off)
- If caching is enabled, check to see if there is a valid cache entry (same parameters, expiry date in the future)
- If that record exists, return the results from the cache table
- If the cached record doesn't exist, run the procedure logic and capture the final results in a temporary table
- If caching is enabled, attempt to populate the cache
- First of all insert the results from the temp table
- Insert the control record and set the expiry date
- Keep a record of the newly inserted cache Id
- If any errors are hit, null out the variable holding cache Id
- If the cache Id isn't null, serve results from the cache
- If the cache Id is null, serve results from the temp table
This procedure features an order by, and so the order by has to be repeated everywhere results are returned to the client.
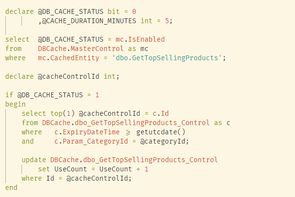
create or alter procedure dbo.GetTopSellingProducts
@categoryId int
as
begin
set nocount on;
declare @DB_CACHE_STATUS bit = 0
,@CACHE_DURATION_MINUTES int = 5;
select @DB_CACHE_STATUS = mc.IsEnabled
from DBCache.MasterControl as mc
where mc.CachedEntity = 'dbo.GetTopSellingProducts';
declare @cacheControlId int;
if @DB_CACHE_STATUS = 1
begin
select top(1) @cacheControlId = c.Id
from DBCache.dbo_GetTopSellingProducts_Control as c
where c.ExpiryDateTime >= getutcdate()
and c.Param_CategoryId = @categoryId;
update DBCache.dbo_GetTopSellingProducts_Control
set UseCount = UseCount + 1
where Id = @cacheControlId;
end
if @cacheControlId is not null
begin
select r.ProductId
,r.TotalSalePrice
from DBCache.dbo_GetTopSellingProducts_Results as r
where r.ControlId = @cacheControlId
order by r.TotalSalePrice desc;
return;
end
select top(20)
p.ProductId
,sum(s.TotalSalePrice) as TotalSalePrice
into #results
from dbo.Sales as s
join dbo.Product as p
on p.ProductId = s.ProductId
where p.CategoryId = @categoryId
and s.SaleDateTime > getutcdate() - 1
and p.AvailableStock > 0
group by p.ProductId
order by sum(s.TotalSalePrice) desc;
if @cacheControlId is null and @DB_CACHE_STATUS = 1
begin
begin try
set @cacheControlId = next value for DBCache.SEQ_Control;
insert into DBCache.dbo_GetTopSellingProducts_Results
(
ControlId
,ProductId
,TotalSalePrice
)
select @cacheControlId
,r.ProductId
,r.TotalSalePrice
from #results as r;
insert into DBCache.dbo_GetTopSellingProducts_Control
(
Id
,CacheDateTime
,ExpiryDateTime
,Param_CategoryId
,UseCount
)
values
(
@cacheControlId
,getutcdate()
,dateadd(minute,@CACHE_DURATION_MINUTES,getutcdate())
,@categoryId
,1
)
end try
begin catch
set @cacheControlId = null;
end catch
end
if @cacheControlId is not null
begin
select r.ProductId
,r.TotalSalePrice
from DBCache.dbo_GetTopSellingProducts_Results as r
where r.ControlId = @cacheControlId
order by r.TotalSalePrice desc;
end
else
begin
select r.ProductId
,r.TotalSalePrice
from #results as r
order by r.TotalSalePrice desc;
end
endClean-up job
The clean-up job implements the following logic:
- Disable caching for the stored procedure in the master control table
- Wait for 45 seconds
- Set lock_timeout to 1 second
- Try to truncate the table
- If we weren't successful, try again up to 5 times
- Mark all cache entries as expired if they are in the future
- Re-enable caching
- If we weren't able to truncate the table, throw an error
The time to wait depends on your environment - if your calling application has a timeout of 30 seconds, then in theory 31 seconds is long enough. In this case we've deployed our wait as timeout x 1.5
create or alter proc DBCache.dbo_GetTopSellingProducts_CleanUp
as
begin
set nocount on;
declare @CONTROL_NAME varchar(255) = 'dbo.GetTopSellingProducts'
,@truncatedResultsTable bit = 0;
update DBCache.MasterControl
set IsEnabled = 0
where CachedEntity = @CONTROL_NAME;
waitfor delay '00:00:45';
set lock_timeout 1000;
declare @retryCount int = 0
,@MAX_RETRY_COUNT int = 5;
while (@retryCount < @MAX_RETRY_COUNT and @truncatedResultsTable = 0)
begin
begin try
truncate table DBCache.dbo_GetTopSellingProductsResults;
set @truncatedResultsTable = 1;
end try
begin catch
set @retryCount += 1;
end catch
end
update DBCache.dbo_GetTopSellingProducts_Control
set ExpiryDateTime = getutcdate()
where ExpiryDateTime > getutcdate();
update DBCache.MasterControl
set IsEnabled = 1
where CachedEntity = @CONTROL_NAME;
if @truncatedResultsTable = 0
begin
;throw 50001, 'Failed to clean up results table for dbo.GetTopSellingProducts', 1;
end
end
goTrade-offs and design decisions
Adding caching in the database is fairly straightforward in theory - we store a copy of the results somewhere and re-use them if they are available (our early prototypes looked very similar to the approach outlined by this post from 2013). Some of the reason's that the caching solution deviated from the simple approach are documented below.
Some of these are specific to the environment the solution is being deployed in, and others are driven by the specific workload we were optimising for. Evaluate your own needs carefully before deploying some or all of this solution into production.
No lock
Not to be confused with nolock! There exist multiple places in this solution where we could have attempted to coordinate access to resources (like results or the control table). We tried a few experiments, and none of them showed sufficient promise to convince us the additional complexity/risk (of long-held locks) was worth it. Our environment is highly transactional and so we opted to avoid any explicit locking, and prefer to duplicate work rather than serialise to perform work only once.
Consider the example when the cache has expired and ten nodes call the procedure - all ten will do the work to populate the cache. This is a fairly extreme example, and in practice we never see this many duplicates (on occasion we do get some double-work).
Being able to easily detect double work was a key driver for instrumentation.
Instrumentation
The caching solution features a UseCount column, which allowed us to monitor the efficacy of the cache when deployed, and verify it was actually delivering value (alongside other measures from QueryStore and application monitoring). The impact of this logging is negligible, and provides us with additional data about how the applications are calling the procedure (as we also know what parameters are being used).
Although a requirement of our implementation, the fact we log every time the cache is populated also allows us to trivially monitor when 2 or more nodes populate the cache at the same time. This is how we're able to confidently say the issue of double-work isn't impacting us.
Adding to the same database vs. a separate database
Our setup features availability groups, and we currently have no IO or networking issues. The benefit of placing the solution in the same database meant we had a much simpler deployment/failover/recovery story.
The main concern deploying it into the primary database is the size of the cache - an early version was deployed to dev without a schedule for the clean-up job - the next morning we woke up to a hot mess of database space alerts.
This example is a very narrow result set with only 20 rows. In production we have deployed this solution on result sets in the 10,000+ rows range with 5+ columns. Being able to benchmark zero impact on our IO latencies was key to our decision to go ahead with a deployment in our primary AG database.
Cache control table
The simplest solution we tried was to store a single copy of the results for any given parameter. Our requirement for no locks as well as clear instrumentation quickly rendered this approach unsuitable.
Adding a second table allowed us to adopt a pattern whereby we'd populate the results before populating the control table. Early implementations populated the control table and then the results table, and under high load/error conditions it was possible for a procedure to think a cached result was ready (as it had checked the control table), only to encounter an empty results table.
Another advantage with a second table was the ability to keep the indexing on the results table very simple, and only have to worry about the parameter-based index on the control table.
Finally, supporting an empty result set isn't possible when only using a results table. Consider a product with no sales - the correct result set has no rows, and the only way to cache that is with a second table in addition to your results table.
Clean-up
Storing expired results meant that clean-up became a critical issue. Initial attempts to run deletes were fairly slow (not to mention expensive compared to a truncate), so we decided that we had to do the work required to support truncating the results table.
The requirement to truncate was the motivation for the master control table - without some kind of coordination we couldn't find a way to safely truncate while the procedures were running. Stopping the procedures being called wasn't possible, but stopping the caching system was something we could support (the cache is a feature which aids performance - the system can run without it, albeit with reduced headroom).
Setting the right frequency of the clean-up job depends heavily on how much data is generated and how much space you can dedicate to the cache solution.
TempDb usage for staging results
This is definitely a tradeoff you should only consider if you are very comfortable with the current state of your tempdb usage, and your ability to monitor it. I'd suggest both tracking global tempdb metrics as well as query-level wait statistics, to ensure you're not unduly bottlenecking on tempdb
The primary motivator for the results table is protection against errors - on encountering any kind of error inserting to the results table we're faced with the option of re-running the expensive logic (or even worse returning nothing!). By staging the data we always have something to return. This has saved us on at least one occasion when a data type change in a base table was not propagated to the cache results table.
A second benefit of this approach is we only need to have one copy of the logic in the procedure. As we support running with DBCache enabled and disabled, an approach which doesn't feature a temp table typically featured a copy of the logic to populate the cache or return the results directly.
Implementing caching
A quick summary of what is needed to cache a procedure
- Create the schema, sequence, and master control table
- Create the control and results table for your procedure
- Create the results clean-up procedure for your procedure
- Schedule the clean-up job to run
- Modify the procedure to include caching
- Until you insert a row in the master control table caching is disabled
- Insert a row in the master control table and turn caching on
The changes to the base proc are fairly intricate, but after you've done it a few times you'll have the pattern down.
There are a few scenarios when you'll probably want to think twice about implementing this solution:
- Huge number of parameters/very large parameters (varchar(max) anyone?)
- Proc is called from a small number of nodes (implement a simpler caching solution)
- IO or TempDB pressure
- Space pressure
Future Ideas
Some additional ideas that have been considered/discussed. The further down this rabbit hole we go the more attractive that shared cache service starts to look!
- Adaptive cache - vary duration by parameter, current load
- Cache bypass - maybe some parameters are cheap enough to not need caching/only cache expensive parameters
- Smart expiry - if data hasn't changed enough don't expire the cache - leverage e.g. Timestamp/CDC
- Rotating partition scheme - truncating trailing partitions and caching into a fresh partition makes the clean-up job more complex but eliminates the need to pause (cache results now keys on PartitionId, ControlId)