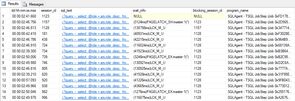
Caching replica state to eliminate HADR_CLUSAPI_CALL waits on dm_hadr_availability_replica_states
We use tsqlscheduler to manage most of our SQL Jobs (a few hundred jobs in a several overlapping AGs), and when lots of schedules overlap (e.g. many concurrent jobs kick off on the hour) we saw waits and blocking on the function that was attempting to determine whether or not the server was the primary replica:
This function queries the DMV sys.dm_hadr_availability_replica_states, and we found that this DMV doesn't perform so well when the cluster size, number of AGs, and number of concurrent queries against the DMV rises.
Querying for the replica's role
select @role = ars.role_desc
from sys.dm_hadr_availability_replica_states ars
inner join sys.availability_groups ag
on ars.group_id = ag.group_id
where ag.name = @availabilityGroupName
and ars.is_local = 1;Under the hood this DMV is calling into the Windows clustering APIs to determine the current status of the replica. There isn't a tonne of information out there - some comments on this SO answer confirm what the DMV is doing, and this MSFT post adds a little more detail. After checking some of the obvious items listed in the second post I decided that maybe we shouldn't be querying the DMV quite so often, and given how rarely the information changes ("is my node the primary replica?") caching this information seemed like a good fit.
Implementing caching
Caching of the replica state is available in any release of tsqlscheduler starting with 1.1. Each task now specifies whether or not it uses the cached replica check or not - most tasks should use the cached replica check, with the exception of the task which keeps the cache updated.
The caching is implemented by a task that persists all replica states for the given AG, and is queried by the GetCachedAvailabilityGroupRole function.
Update replica status
create or alter procedure scheduler.UpdateReplicaStatus
as
begin
set nocount on;
set xact_abort on;
declare @availabilityGroup nvarchar(128);
select @availabilityGroup = ag.AvailabilityGroup
from scheduler.GetAvailabilityGroup() as ag;
merge scheduler.ReplicaStatus as rs
using (
select ar.replica_server_name, ars.role_desc
from sys.dm_hadr_availability_replica_states ars
inner join sys.availability_groups ag
on ars.group_id = ag.group_id
join sys.availability_replicas as ar
on ar.replica_id = ars.replica_id
where ag.name = @availabilityGroup
) as src
on src.replica_server_name = rs.HostName
and src.role_desc = @availabilityGroup
when matched then
update
set rs.AvailabilityGroupRole = src.role_desc
when not matched then
insert ( AvailabilityGroup, HostName, AvailabilityGroupRole )
values ( @availabilityGroup, src.replica_server_name, src.role_desc )
when not matched by source
then delete;
endGet cached role
create or alter function scheduler.GetCachedAvailabilityGroupRole
(
@availabilityGroupName nvarchar(128)
)
returns nvarchar(60)
as
begin
declare @role nvarchar(60);
select @role = rs.AvailabilityGroupRole
from scheduler.ReplicaStatus as rs
where rs.AvailabilityGroup = @availabilityGroupName
and rs.HostName = host_name();
return coalesce(@role, N'');
end
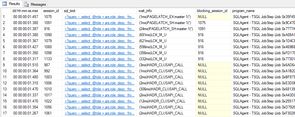
Deploying these changes eliminated the blocking behaviour, and we've seen the back of some fairly spectacular blocking chains we were able to produce when a server was under heavy load (yes, that is almost 3 minutes waiting to decide if the task can even run or not!).