Keeping a work journal with VS Code
I've recently started to keep a work journal, and aside from being an incredibly useful document, it also gave me an excuse to learn a lot more about VS Code. After publishing an extension for VS Code yesterday, I'm now declaring my work journal flow done (at least for now...), and the rest of this post will walk you through my setup.
Workflow goals
In setting up a workflow there were a few requirements I had:
- Easy to get up and running on a new machine
- Easy to run on multiple machines (home/work/laptops)
- Minimum possible friction to add something to the journal
- Works in VS Code (my go-to editor for anything that doesn't merit VS2017 or SSMS)
The first two points boil down to sync, and crucially that sync should contain not only the journal itself but also the settings used to help achieve the third point (minimum friction edits) on every machine.
Keeping things in sync
The journal itself lives in a repository in Visual Studio Team Services, in which it is free to host unlimited repos for up to 5 users. Having access to a repo either by SSH (which I use on most permanent machines) or via a Microsoft login (which allows for quick in-browser edits in a pinch) is helpful. I'd have probably gone with GitHub if I had a plan which supported private repos.
In order to keep the VS Code configuration in sync I use the Settings Sync extension, which uses a private GitHub gist (which is free!) to sync settings between instances of VS Code. With this configured all extensions/user settings/keybindings/etc., are synced between all instances of VS Code. It's awesome.
Configuring the editor
Aesthetics aside (Solarized Light and the Fira Code font if you're curious), the most important actions I take on the journal are:
- Pull from the repo
- Add a timestamp
- Add, Commit, and Push changes
The pull/push typically bookend my day with each machine I work at. Pulling from the repo is easy (builtin command), but adding a timestamp and the add/commit/push combination don't have an in-built solution.
For the timestamp I use the Insert Date String extension configured with the following custom format:
"insertDateString.format": "DDD MMM DD hh:mm:ss YYYY\n"Binding this to a key means hitting the key inserts a timestamp and puts the cursor on a newline.
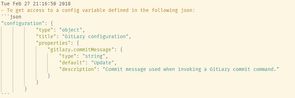
Solving for add/commit/push was actually much harder than I thought it would be, and after looking at a few extensions which came close (like Git Urgent! and Git Add & Commit) I ended up writing my own extension - GitLazy.
Although it was a fairly simple addon, it was my first extension and my first look at TypeScript, so I've learned a whole lot from that. In terms of time saved vs. time spent I think it should pay off in...a few years! My default commit message is configured as:
"gitlazy.commitMessage": "Update journal"Putting it all together
One of the first things I do after logging in to a machine is now go to the second desktop (I'm using Windows 10), open my journal VS Code workspace, and put it into Zen mode (CTRL-K, Z by default). From that point on I'll flip back to that desktop (WinKey+Ctrl+Right) whenever I want to log something.
I use markdown by default, and most of the time log code in appropriately delineated blocks (as per the above screenshot), though I don't mind simply pasting something in if I want to keep it for reference.
Coming soon
Given the amount of time I spent optimising the flow of add/commit/push I find it highly unlikely I'll be able to leave the flow alone for too long. I've considered making the code workspace a startup task, or even pinning the workspace to the start menu for even faster switching (e.g. WinKey+1).
I'm debating right now whether or not to put some outputs from meetings in the journal or not - for 1:1s I typically keep notes organised per-person (in addition to a shared agenda) on something like OneNote or a word document in SharePoint. I'm now wondering if they should also get dumped into the log, or if perhaps migrating them to source-controlled markdown is a better format.
I'm also looking forward to writing something to parse out the journal, not to gain anything in particular from it right now, more because it'll be a chance to write some parsing code and see what can be done with the data...