Mitigating SERVICE_BROKER_WAITFOR_MANAGER latch waits
Our production environment recently started generating alerts on huge blocking chains (100s of requests), which were accompanied by increased database response times for various procedures. The blocking chains all had the latch wait SERVICE_BROKER_WAITFOR_MANAGER in common, some of which were blocking for seconds (adding significant overhead to operations that would normally complete in a few milliseconds).
In this post I'll walk through what an environment leveraging service broker might look like, show you how to reproduce the issue, and offer some mitigation strategies/general advice for service broker at scale.

Service Broker Recap
SQL Service Broker (SSB) can be used as a messaging system to decouple applications. Note that SSB is a complex product and this specific example only covers one way it can be used (or perhaps misused).
Imagine a website application wants to process a card payment - the website would queue a process_payment message (to a SSB queue). That SSB queue is monitored by a separate payment application. The payment application would receive the process_payment message, process the payment, and respond to the website with the result. This is an example of a dialog (two-way) conversation.
SSB also supports fire and forget (care needs to be taken to ensure it is implemented correctly), which you might use if the website wants to send an email, but doesn't need to wait for the result (the website puts an order_confirm_email message on a SSB queue, and the email application processes it from that queue at some point in the future). Background processes can also take advantage of fire and forget to queue up a large amount of work - imagine an email for newsletter_mail for every subscriber.
In a complex application there can be dozens or hundreds of different messages and queues, and multiple applications queueing/dequeueing messaging. Scaling SSB to cope with high throughput is a challenge of it's own (see this whitepaper on scaling SSB from 2009) - the specific scaling challenge I'll discuss in this post relates to waiters (applications waiting to dequeue messages from a queue).
Each queue can have 0 to N requests waiting to process (dequeue) a message. While you could have applications check each queue periodically (polling with receive), SSB allows you to register and 'wait' on a queue, such that the request will block until a message arrives, at which point it will be returned to the calling application. You do this with the waitfor keyword. In our environment we use waitfor to ensure each queue has a minimum of 1 waiter at all times.
The final bit of background needed is that you can use event notifications to have SQL Server notify you when there are messages waiting to be processed on a queue (specifically with the QUEUE_ACTIVATION event). We use this to create additional threads (which call the queue with waitfor) to process multiple messages concurrently.
In summary:
- One queue per decoupled process
- At least one reader per-queue
- The number of readers per-queue will scale as there are more messages to process
- The way readers interact with the queue is via the waitfor keyword
- This pattern is used for both dialogs (two-way) and fire and forget (one-way) messaging
- Dialogs are typically latency sensitive (we care about the response time)
- Fire and forget are typically latency insensitive, and can be very high volume
The problem
It starts with alerts for blocking in production. The environment in question normally never has anything but transient (<100ms) blocking, so to see an alert go off with a few seconds of blocking involving hundreds of requests was...disconcerting! The blocking alert helpfully pointed the finger at service broker (SERVICE_BROKER_WAITFOR_MANAGER), though after a quick Google we assumed we were on our own (when the latch waits library says TBD, typically you're in trouble).
In this case however the Microsoft latch docs had us covered. Most of the time 'Internal use only' is all you get, but in this case case the description gave us a few concrete avenues to investigate:
Used to synchronize an instance level map of waiter queues. One queue exists per database ID, Database Version, and Queue ID tuple. Contention on latches of this class can occur when many connections are: In a WAITFOR(RECEIVE) wait state; calling WAITFOR(RECEIVE); exceeding the WAITFOR timeout; receiving a message; committing or rolling back the transaction that contains the WAITFOR(RECEIVE); You can reduce the contention by reducing the number of threads in a WAITFOR(RECEIVE) wait state.
Armed with this, and after checking to see if this was actually leading to increases in response time for latency-sensitive calls (it was), I set out to try and isolate and remedy the waits.
Reproduction
Setup
To reproduce the issue all we need is a single queue, and a way of generating concurrent activity against that queue. Note that This does not constitute what a real deployment of SSB looks like (with multiple queues, request/response services, priorities, etc.).
In order to generate load against the queues I used SQLDriver - you can download the SQLDriver 1.0 standalone binaries, or use any other stress testing tool. Crucially, you want to ensure your tool will tell you about the response times and not just the total runtime.
The database and schema look like this:
create database BrokerTest
go
use BrokerTest
go
alter database current set enable_broker;
create master key encryption by password = 'secure';
go
alter database current set compatibility_level = 140;
alter database current set recovery simple;
alter database current set delayed_durability = forced;
go
create queue dbo.TestQueue;
create queue dbo.TestQueue1;The reason we set delayed durability to forced is to minimise/eliminate any WRITELOG waits. Although it doesn't appear to be documented anywhere, calling waitfor(receive...) will generate transaction log - even when called on a totally empty queue.
To start with I ran a load test and looked at sp_whoisactive to confirm the wait was showing up. The following command will run 100 concurrent waitfor-receives, each with a timeout of 1ms. Each thread will execute the statement 10000 times.
SqlDriver.exe
-s "waitfor(receive top(1) * from dbo.TestQueue), timeout 1"
-t 100
-r 1000
-c "server=localhost;initial catalog=BrokerTest;integrated security=SSPI;Application Name='SQLDriver';max pool size=1024"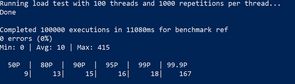
The numbers that I'll focus on for the rest of the post are the median response time (P50), and the tail latency (P95). In the above example the median response time was 9ms, and the 95th percentile response time was 16ms. In a typical system the timeout would be much higher than 1ms (at such a low timeout we might as well be polling the server), and even with a single thread we'd see variation with timeouts < 10ms - though most of the wait time would be the benign wait BROKER_RECEIVE_WAITFOR.
Eyeballing the waits for this first test I did see the expected latch waits (both LATCH_SH and LATCH_EX for SERVICE_BROKER_WAITFOR_MANAGER), though I also saw the wait type WAITFOR_PER_QUEUE. This wait type is not documented, and seems to indicate there is a maximum number of waiters per queue. In additional testing I got up to 700 concurrent waiters on one queue (before my laptop ran out of worker threads), so this wait appears to be linked with registering a waitfor, rather than the total number of waiters.
Load testing - single queue
To ensure there were no other waits being missed by eyeballing sp_whoisactive, I used an extended event trace for all waits coming from the SQLDriver application.
if exists ( select * from sys.server_event_sessions where name = 'SQLDriverLatches' )
drop event session SQLDriverLatches on server;
go
create event session SQLDriverLatches on server
add event sqlos.wait_info (
where sqlserver.client_app_name = N'SQLDriver'
and opcode = 1 /* End - otherwise we get the start & end of every wait */
and duration > 0
)
add target package0.asynchronous_file_target (
set filename = N'C:\temp\SQLDriverLatches.xel'
)
with (
max_dispatch_latency = 1 seconds
);
go
alter event session SQLDriverWaits on server state = start;
/* Run the load test! */
alter event session SQLDriverWaits on server state = stop;Creation of the extended event session and the analysis heavily borrows from Paul Randall's post on session level wait stats
The results can be analysed with the following SQL - the .xel files should be deleted between each test. Note that this query can take a long time if there are a large number of waits to analyse.
drop table if exists #xetemp;
select cast(event_data as xml) as EventData
into #xetemp
from sys.fn_xe_file_target_read_file ('C:\temp\SQLDriverWaits*.xel',null,NULL,NULL);
select dat.WaitType
,count(*) as WaitCount
,sum(dat.Duration) as WaitTime
,sum(coalesce(dat.SignalDuration,0)) as SignalWaitTime
from #xetemp as x
cross apply (
select x.EventData.value('(/event/data[@name=''wait_type'']/text)[1]','varchar(100)') as WaitType
,x.EventData.value('(/event/data[@name=''duration''])[1]', 'bigint') as Duration
,x.EventData.value('(/event/data[@name=''signal_duration''])[1]', 'bigint') as SignalDuration
) as dat
group by dat.WaitType
order by count(*) descThe extended event trace only tells us there is a latch wait (LATCH_EX/LATCH_SH), but not the specific latch being waited on. To track that, I cleared the latch stats DMV before each load test, and then grabbed the results after:
dbcc sqlperf('sys.dm_os_latch_stats', clear);
/* Run the load test! */
select * from sys.dm_os_latch_stats
order by wait_time_ms desc;I ran benchmarks for 1, 10, 100, 200, and 300 threads - each with 1000 repetitions of a waitfor-receive that has a 10 millisecond timeout. In the below table, SWM Average refers to the average amount of time waiting on the SERVICE_BROKER_WAITFOR_MANAGER latch - computed from the DMV as wait_time_ms / waiting_requests_count. Note a thread can acquire latches multiple times during each request, the averages below represent per-latch request attempt.
| Threads | 50P | 95P | SWM Average |
|---|---|---|---|
| 1 | 15ms | 15ms | 0ms |
| 10 | 15ms | 16ms | 0.36ms |
| 100 | 22ms | 33ms | 3.59ms |
| 200 | 32ms | 41ms | 5.76ms |
| 300 | 51ms | 64ms | 9.44ms |
Querying for wait type mainly served to confirm the dominant waits are for latches (plus a smattering of the rogue WAITFOR_PER_QUEUE). Examining average latch time shows how this wait type increases along with response time, both median and tail latency.
A high thread count against a single queue will bottleneck on this latch - but what impact does that have if we introduce a second queue?
Load testing - second queue
A common pattern we saw in the blocking alerts was high-volume queues (many messages, and lots of concurrent threads) appeared to be impacting the performance of low-volume queues.
To reproduce this behaviour I started 100 threads with a high repetition count against dbo.TestQueue, and then load tested with low thread count against dbo.TestQueue1 with a second instance of SQLDriver.
For this benchmark we're not able to use the latch stats DMV (as the activity against the first queue will dominate), so we'll look at the response times only.
To capture wait stats related to the second queue only we modify the application name property of the 'background' connection string:
SqlDriver.exe
-s "waitfor(receive top(1) * from dbo.TestQueue), timeout 10"
-t 100
-r 10000000
-c "server=localhost;initial catalog=BrokerTest;integrated security=SSPI;Application Name='SQLDriverBackground';max pool size=1024"The requests against the second queue (from a single thread) have a median response time of 15ms, and 95th percentile response time of 27ms. The main waits logged are LATCH_EX and LATCH_SH again, and the latch stats DMV confirms no new latches have shown up.
The second queue is impacted by activity against the first queue - this makes sense as the latch is instance-wide.
Load testing - summary
The latency to acquire the SERVICE_BROKER_WAITFOR_MANAGER latch increases as the number of total concurrent waitfor-receive registrations increases, regardless of the queue.
As an added bonus, there is a mystery wait (WAITFOR_PER_QUEUE) you will run into with a high number of waitfor-receives attempting to register concurrently against a single queue.
So what can we do about it?
Mitigating the problem
The good news is there is a relatively easy workaround - don't wait(for)!
Repeating the previous load test but changing the second queue to be receive (not waitfor-receive) gives a median response time of 0ms, 95th percentile response time of 0ms - and no waits.
This is unlikely to be a change you'll want to make to your application directly, as you'll now be doing 1000 RPS per thread against the server for every queue being received from (assuming a latency of ~1ms).
Instead, we can deploy a receive with a sleep, with the sleep acting as our upper bound for response time. In the worst case you start sleeping right after a message arrives, so you'll wait the sleep duration and then when the next request executes the message will be dequeued.
The SQL for a receive with sleep might look something like this:
receive top(1)
conversation_handle,
cast(message_body as xml),
message_type_name
from dbo.TestQueue;
if @@rowcount = 0
begin
waitfor delay '00:00:01';
end;Other observations
Having hundreds of threads sitting in a waitfor-receive (with high timeout values) had no noticeable impact on new threads registering a waitfor-receive, either on the same or different queues.
The Microsoft latch docs indicate this latch only comes into play when you're modifying the list of waitfors, and so on busy systems where there is lots of concurrent dequeue activity I'd expect similar bottlenecks to manifest (dequeueing a message into an existing waitfor also needs to modify the waitfor list, which means it needs the latch).
General Advice
This problem is a great example of something that more hardware can't fix - no amount of additional cores will help alleviate an instance-wide latch bottleneck. One of the most interesting parts of scaling up a SQL Server is all the wonderful new bottlenecks you discover - higher core counts (and workloads to drive those cores) make it easier to find concurrency bottlenecks (at lower core counts worker thread starvation will probably get you before you hit this latch).
If you are currently using SSB and think you may end up with hundreds of threads performing operations against SSB queues:
- For low latency sensitivity (don't care about response time) - use receive + sleep
- At low volume and high latency sensitivity - use waitfor-receive
- If you need high volume and you have high latency sensitivity...look elsewhere
In many cases the scale and performance you need to achieve might require you to architect away from SSB:
- Perfectly tuned, SSB cannot meet your requirements
- You don't have (or want to build) the expertise needed to tune SSB
- Other solutions give comparable or superior performance, the cost to migrate is low
These are especially true when you don't need some of the unique features SSB provides (multicast messaging, routing between multiple databases, poison message handling...). Those features come with a performance price!
The story of how we found ourselves with so much SSB I think is fairly typical. The pattern we adopted was a victim of it's own success, and so went from being used in a few places to being used everywhere. Only recently have these bottlenecks started to show up, and a gradual shift to other solutions is letting us break through successive scale barriers.
Some of those solutions involve switching to dedicated message queue product (e.g. RabbitMQ), and some have involved moving away from queues entirely (e.g. GRPC). Some of the more successful (measured as low implementation cost/high performance gain) have been switching queues out for tables (either regular or in-memory).